Ziel und Problemstellung: Ziel des Projektes war der Aufbau einer vollständig lokalen, datenschutzfreundlichen KI-Umgebung, die unabhängig von Cloud-Anbietern arbeitet und sowohl kreative als auch analytische Aufgaben übernehmen kann. Der Fokus lag dabei auf: lokaler Sprachmodell-Inferenz, lokaler Sprachsynthese, modularen Multi-Agent-Systemen, persistentem Wissensmanagement, sowie der Vorbereitung zukünftiger autonomer KI-Agenten.
Ergebnisse: Die Entwicklung erfolgte schrittweise und orientierte sich an praktischen Anwendungsfällen. Es wurden diverse Erfahrungen gesammelt und das Wissen mithilfe der erwähnten Gaming-Maschine angewendet.
Übersicht
Das Projekt entwickelte sich von einer lokalen LLM-Installation zu einer modularen Multi-Agent-Plattform für kreative und analytische Aufgaben.
Die wichtigsten Erkenntnisse waren:
- Architektur ist wichtiger als Modellgröße.
- Spezialisierte Agenten sind leistungsfähiger als universelle Modelle.
- Persistentes Wissen ist entscheidend für Langzeitprojekte.
- Lokale KI-Systeme können bereits heute komplexe Agentenarchitekturen unterstützen.
- Die Zukunft liegt weniger in einzelnen Modellen als in kooperierenden lokalen KI-Agentensystemen.
Aufgrund der Tiefe und der Ergänzungen durch KI wird dieser Artikel aufgeteilt!
Das Titelbild wurde übrigens mit ChatGPT5o erstellt.

Phase 1: Aufbau der lokalen KI-Infrastruktur
Problemstellung
Cloudbasierte KI-Dienste verursachen:
- laufende Kosten,
- Datenschutzprobleme,
- API-Abhängigkeiten,
- begrenzte Anpassbarkeit,
- eingeschränkte Offline-Fähigkeiten.
Es sollte daher eine vollständig lokale Infrastruktur aufgebaut werden.
Ziele
- Vollständig lokaler Betrieb
- Docker-basierte Architektur
- Unterstützung verschiedener Open-Source-Modelle
- Austauschbare Komponenten
- Hardwarebeschleunigung über GPU
- Integration in OpenWebUI
Umsetzung
Die Infrastruktur basiert auf:
- Docker
- Ollama
- OpenWebUI
- NVIDIA GPU-Beschleunigung
- Reverse Proxy Infrastruktur
Dadurch entstand eine modulare lokale KI-Plattform, auf der verschiedene Sprachmodelle parallel betrieben werden können.
Phase 2: Lokale Sprachsynthese mit Supertonic-3
Problemstellung
Neben der Textgenerierung sollte auch eine vollständig lokale Sprachsynthese ermöglicht werden.
Dabei traten insbesondere bei der Integration verschiedener OpenAI-kompatibler Clients zahlreiche Kompatibilitätsprobleme auf.
Ziele
- Lokale TTS-Inferenz
- OpenAI-kompatible API
- Integration in OpenWebUI
- Unterstützung von Browser-Clients
- Verzicht auf Cloud-TTS
Architektur
Read Aloud
│
▼
OpenAI-kompatibler Proxy
│
▼
Supertonic-3
│
▼
Lokale Sprachsynthese
Implementierte Lösungen
OpenAI-kompatibler Proxy
Der Proxy übernimmt:
- CORS
- OPTIONS-Requests
- API-Anpassungen
- Fehlerbehandlung
- Request-Transformation
Emulierte OpenAI-Endpunkte
Unter anderem:
/v1/models
/v1/audio/speech
Audio-Konvertierung
Automatische Anpassung zwischen:
- MP3
- WAV
Fehlerbehebung
Gelöst wurden unter anderem:
- fehlende API-Endpunkte,
- fehlerhafte Payloads,
- Content-Length-Probleme,
- Unicode-Fehler,
- Browser-Inkompatibilitäten.
Ergebnis
Es entstand eine vollständig lokale, OpenAI-kompatible Sprachsyntheseplattform.
Phase 3: Entwicklung einer lokalen Multi-Model-Schreibpipeline
Problemstellung
Einzelne Sprachmodelle zeigten bei längeren Projekten erhebliche Schwächen:
- Stilbrüche,
- Inkonsistenzen,
- Plotfehler,
- Lore-Verlust,
- hohe Rechenkosten.
Es wurde daher eine rollenbasierte Multi-Agent-Architektur entwickelt.
Ziele
Funktional
- Trennung von Schreiben und Review
- Persistentes Memory
- Iterative Verbesserung
- Unterstützung großer Projekte
Technisch
- Vollständig lokal
- Modulare Architektur
- Austauschbare Modelle
- Hohe Skalierbarkeit
- Robuste Wiederaufnahme
Erste Implementierung: Python-Pipeline
Die erste Version entstand als lineare Python-Pipeline.
WRITE-Modus
Idee
↓
Writer
(Mistral Small 3.2)
↓
Review
↓
Merge
(Nemotron Cascade)
↓
Memory
(Nemotron Nano)
REVIEW-Modus
Kapitel
↓
Review0
(Nemotron Nano)
↓
Review1
(Qwen)
↓
Review2
(Gemma)
↓
Merge
(Nemotron Cascade)
↓
Memory
Modellrollen
| Rolle | Modell | Aufgabe |
|---|---|---|
| Writer | Mistral Small 3.2 | Kreative Texterstellung |
| Review0 | Nemotron Nano | Schnelle Vorprüfung |
| Review1 | Qwen 3.5 | Struktur, Logik, Lore |
| Review2 | Gemma 4 | Stil und Konsistenz |
| Merge | Nemotron Cascade 2 | Konsolidierung |
| Memory | Nemotron Nano | Wissensextraktion |
Memory-System
Für jedes Kapitel werden erzeugt:
- Zusammenfassungen
- Charakterdaten
- Orte
- Fraktionen
- Ereignisse
- Regeln
- Zeitachsen
- Embeddings
Workflow:
Kapitel
↓
Analyse
↓
Zusammenfassung
↓
Metadaten
↓
Embedding
↓
Memory
Batch-Review-System
Später wurde die Architektur erweitert:
Kapitel 1..N
↓
Mistral Review
Qwen Review
Gemma Review
↓
Kapitel-Merge
↓
Globaler Merge
↓
Memory Update
Dadurch konnten komplette Werke analysiert werden, bevor gezielte Überarbeitungen erfolgten.
Erkenntnisse
Es zeigte sich, dass:
- kleine Spezialmodelle oft effizienter arbeiten als große Universalmodelle,
- unterschiedliche Modellfamilien systematische Fehler reduzieren,
- ein gutes Merge-Modell wichtiger ist als ein sehr großes Schreibmodell,
- Analyse und Schreiben getrennt werden sollten.
Ergebnis
Erreicht wurden:
- lokale Multi-Agent-Pipeline,
- persistentes Memory,
- Batch-Review,
- iterative Überarbeitung,
- automatische Qualitätskontrolle,
- Wiederaufnahme unterbrochener Läufe,
- modulare Rollenarchitektur.
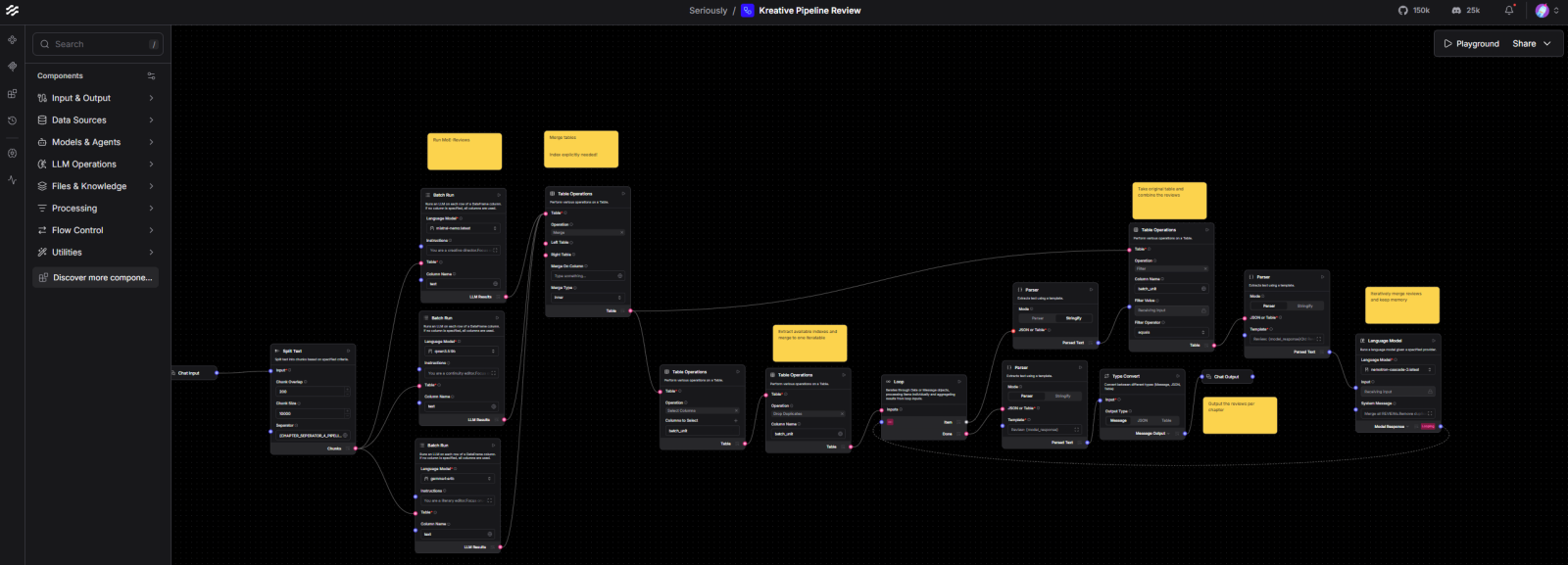
Sichtbar im Bild unten ist ein Sinnbild für diese Pipeline.
Phase 4: Integration semantischer Recherche- und Wissensagenten (Vane / Perplexica)
Problemstellung
Bis Phase 3 wurde eine Multi-LLM-Pipeline gebaut; ab Phase 4 beginnt der Übergang zu einer lokalen Agenten- und Wissensarchitektur. Basis dafür ist Wissenskollektion. Da die reine Multi-Model-Schreibpipeline zwar kreative Texte erzeugen, analysieren und konsolidieren konnte, war sie jedoch weiterhin auf den aktuell übergebenen Kontext beschränkt. Dies führte insbesondere bei komplexen Projekten zu Problemen wie:
- fehlendem externen Fachwissen,
- begrenzter Kontextgröße,
- unvollständigem Worldbuilding,
- mangelnder Quellenvalidierung,
- schwieriger Navigation großer Wissensbestände.
Es entstand daher die Anforderung, ein semantisches Recherche- und Retrieval-System in die lokale Pipeline zu integrieren.
Ziele
- Erweiterung der lokalen Pipeline um Retrieval-Augmented Generation (RAG)
- Integration lokaler und externer Wissensquellen
- Semantische Dokumentensuche
- Automatische Kontextanreicherung
- Unterstützung von Faktenprüfung und Recherche
- Vorbereitung agentischer Workflows
Vane / Perplexcia 2.0
Die Untersuchung von Perplexica (Perplexcity, nur open-source) als lokaler Such- und Recherche-Agent hat folgendes ergeben:
Widmungen:
- kontextabhängige Wissensaggregation,
- semantische Navigation,
- projektübergreifendes Gedächtnis,
- Unterstützung autonomer Agenten.
Eigenschaften:
- lokaler Betrieb,
- Websuche,
- Retrieval-Augmented Generation,
- Quellenangaben,
- OpenAI-kompatible Schnittstellen.
Angedachte, erweiterte Architektur
Benutzer
│
▼
WRITE / REVIEW Pipeline
│
▼
Memory-System
│
▼
Vane / Perplexica
│
▼
Semantische Recherche
│
▼
Kontextanreicherung
│
▼
LLM-Agenten
Erkenntnisse
Die Untersuchungen zeigten, dass zukünftige lokale KI-Systeme weniger aus einzelnen Sprachmodellen bestehen werden, sondern aus:
- spezialisierten Agenten,
- persistentem Langzeitgedächtnis,
- semantischen Suchsystemen,
- Retrieval-Komponenten,
- dynamischen Workflow-Engines.
Dabei wurde deutlich, dass:
- die Qualität der Wissensbeschaffung häufig wichtiger ist als die Größe des verwendeten Sprachmodells,
- lokale Retrieval-Systeme Halluzinationen erheblich reduzieren können,
- semantische Suche und Memory-Systeme zentrale Bestandteile zukünftiger Agentenarchitekturen darstellen.
Ergebnis
Die Integration von Vane und Perplexica markierte den Übergang von einer reinen Multi-LLM-Schreibpipeline hin zu einer allgemeinen lokalen Wissens- und Agentenplattform.
Damit wurde die Grundlage geschaffen für:
- agentische Workflows,
- semantisches Langzeitgedächtnis,
- autonome Recherche,
- wissensgestützte Generierung,
- sowie zukünftige lokale Multi-Agent-Systeme.
Phase 5: Übergang zu graphbasierten Agentensystemen & Ausblick auf lokale KI-Agenten
Die Python-Pipeline zeigte, dass komplexe Arbeitsabläufe nicht mehr linear beschrieben werden können. Die entwickelte Architektur eignet sich nicht nur für kreatives Schreiben, sondern allgemein für:
- Dokumentanalyse,
- Wissensmanagement,
- Projektplanung,
- Langzeitgedächtnis,
- Qualitätskontrolle,
- semantische Suche,
- autonome Agentensysteme.
Bereits heute zeigt sich, dass lokale Modelle über Ollama erfolgreich in Entwicklungsumgebungen integriert werden können, beispielsweise in:
- Visual Studio Code,
- OpenWebUI,
- Agentenframeworks,
- lokalen Toolchains.
Da dies aber bislang auf einer Basis an Frameworks und eher "simplen" 600 Zeilen an Python-Code, der dazu verdammt sein wird nicht wartbar zu sein, basiert habe ich mich auf langfristig sinnvollere Methoden besinnt. Daher begann die Migration zu graphbasierten Agentensystemen.
Ziele:
- zustandsbasierte Agenten,
- persistente Workflows,
- parallele Verarbeitung,
- semantisches Retrieval,
- autonome Entscheidungsprozesse.
Hierfür werden aktuell insbesondere folgende Frameworks untersucht:
- LangGraph,
- LangFlow, (als aktueller Fokus, und sichtbar im Bild unten)
- Flowise.
Dadurch entsteht langfristig eine vollständig lokale KI-Arbeitsumgebung, die nicht mehr aus einzelnen Modellen besteht, sondern aus spezialisierten, kooperierenden Agentensystemen.